-
SOM 자기조직화지도<ML> 2023. 1. 2. 18:16728x90
1. 기본 구조
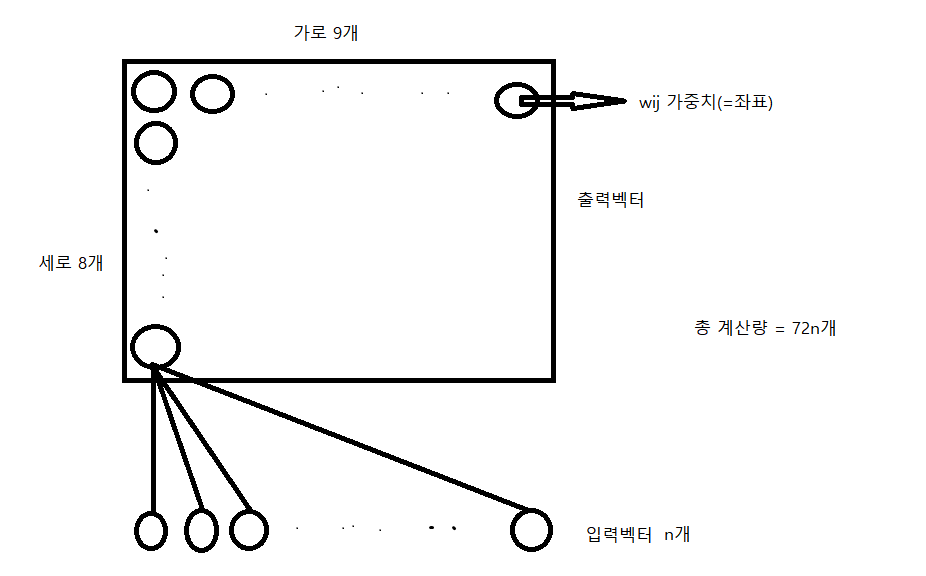 상단의 2차원 그림은 output벡터이다. (위는 예시일뿐, 2차원뿐 아니라 3차원, ... , n차원 가능)가중치 wij는 가중치라기 보단 해당 뉴런의 좌표 위치이다. (xk,yk) 총 가로8x세로9 = 72개의 wij인공신경망의 원리를 이용했다는 것은 다른게 아니라 fully-connected로 연결되는 것(=좌표 사이의 모든 거리를 구한다.)을 보여주는 것이다.input vector n개 x output vector 72개 = 총 72n개의 계산량2. 알고리즘 구조
상단의 2차원 그림은 output벡터이다. (위는 예시일뿐, 2차원뿐 아니라 3차원, ... , n차원 가능)가중치 wij는 가중치라기 보단 해당 뉴런의 좌표 위치이다. (xk,yk) 총 가로8x세로9 = 72개의 wij인공신경망의 원리를 이용했다는 것은 다른게 아니라 fully-connected로 연결되는 것(=좌표 사이의 모든 거리를 구한다.)을 보여주는 것이다.input vector n개 x output vector 72개 = 총 72n개의 계산량2. 알고리즘 구조자기조직화지도 인공신경망 기법중에서 가장 단순한 알고리즘 중 하나이다. 알고리즘에서 입력 벡터와 경쟁층 노드간의 거리를 나타내는 DijDij와 노드의 가중치를 수정하는 연산은 항목 4에 따로 설명한다. 자기조직화지도에서 알고리즘을 실행하거나 종료하기 위해서는 현재 입력 벡터와 현재 반복 횟수, 두 개의 값을 유지해야 한다. 자기조직화지도 알고리즘은 아래와 같다.
1) 가중치 행렬 각 원소의 값을 임의의 0보다 크고 1보다 작은 값으로 초기화
2-1) 입력 벡터와 경쟁층에 존재하는 jj개의 노드에 대해 입력 벡터와 노드 간의 거리 DijDij를 계산
2-2) 현재 입력 벡터와 DijDij값이 가장 작은 경쟁층의 노드를 선택
2-3) 해당 노드의 가중치와 이웃 노드의 가중치를 수정
5) 현재 입력 벡터가 마지막 입력 벡터라면 다음 과정으로 이동하고, 그렇지 않다면 과정 2로 돌아간다
6-1) 현재 반복 횟수가 최대 반복 횟수라면 알고리즘을 종료
6-2) 현재 반복 횟수가 최대 반복 횟수가 아니면 현재 입력 벡터를 처음 입력 벡터로 설정하고 과정 2로 돌아간다
 3. 연산 정의
3. 연산 정의입력 벡터와 노드 간의 DijDij는 아래와 같이 정의된다.
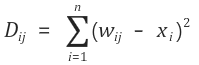
위의 수식에서 nn은 입력 벡터의 크기, wijwij는 가중치 테이블에서 ii행 jj열의 값을 나타낸다. 그리고 가중치와 뺄셈 연산을 하는 xixi는 입력 벡터의 ii번째 값을 뜻한다.
경쟁층의 노드를 선택한 다음 해당 노드의 가중치를 수정하는 연산은 아래와 같다.
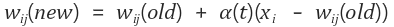
위의 식에서 wij(new)wij(new)는 새로운 가중치, wij(old)wij(old)는 이전 가중치를 뜻한다. 그리고 우변의 두번째 항에 있는 a(t)a(t)는 학습률을 나타내며, 알고리즘을 설계할 때 정하는 값으로 알고리즘이 반복될 수록 값이 작아진다.
4. 예제4개의 입력 벡터를 2개의 그룹으로 클러스터링하는 자기조직화지도(SOM)을 설계한다. 자기조직화지도에 입력되는 4개의 입력 벡터는 아래와 같다.
(1, 0, 0, 1) (0, 0, 1, 1) (0, 1, 0, 1) (0, 0, 1, 0)
입력 벡터를 2개의 그룹으로 클러스터링 하므로 경쟁층 노드의 수는 2이다. 자기조직화지도의 최대 반복 횟수는 10,000번으로 설정한다. 초기 학습률은 0.6으로 설정하고, 한번의 연산이 끝나면 학습률은 이전 학습률의 0.4배로 변경한다. 따라서 다음 단계의 학습률은 아래와 같이 계산된다.
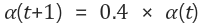
경쟁층의 노드의 수가 2개 뿐이기 때문에 이웃 노드의 개념은 없다고 가정한다. 출력층 노드의 수가 많은 자기조직화지도에서는 가중치가 수정되는 노드의 이웃 노드도 같이 가중치를 수정해준다.
1) 초기 가중치 행렬 초기화
입력 벡터의 크기가 4이고 출력층 노드의 수가 2이므로 가중치 행렬의 크기는 4 X 2이다. 가중치 행렬 각 원소의 값은 0 ~ 1 범위에 있는 임의의 값으로 초기화한다. 임의의 값으로 초기화한 가중치 행렬은 아래와 같다고 가정한다.

2) 입력 벡터와 경쟁층 노드의 거리 계산 및 가중치 수정
입력 벡터와 경쟁층 노드의 거리를 계산하는 식은 아래와 같다.
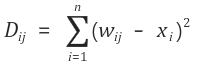
2-1) 첫 번째 입력 벡터 (1, 0, 0, 1)에 대해 연산
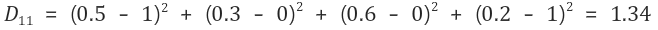
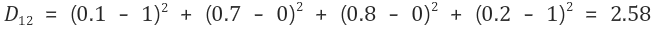
그러므로 첫 번째 입력 벡터는 경쟁층의 첫 번째 노드와 가장 가깝다. 경쟁층의 첫 번째 노드가 선택되었으므로, 첫 번째 노드에 대한 가중치를 수정한다.
새로운 가중치는 아래와 같이 계산된다.
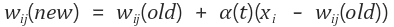
예를 들어 경쟁층 첫 번째 노드의 현재 두 번째 가중치인 0.3은 아래와 같은 식에 의해 0.12로 변경된다.

위의 식에서 0.6은 앞에서 설정한 학습률이다. 이러한 방식으로 경쟁층 첫 번째 노드의 가중치를 모두 수정하면 가중치 테이블은 아래와 같이 변경된다.

2-2) 두 번째 입력 벡터 (0, 0, 1, 1)에 대해 연산
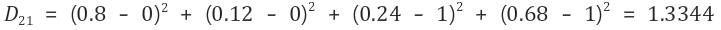

그러므로 두 번째 입력 벡터는 경쟁층의 두 번째 노드와 가장 가깝다. 경쟁층의 두 번째 노드가 선택되었으므로, 두 번째 노드에 대한 가중치를 수정한다. 수정된 가중치 행렬은 아래와 같다.
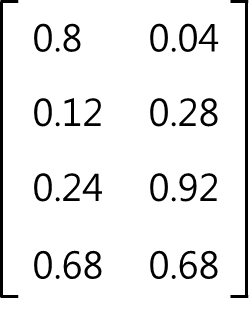
2-3) 세 번째 입력 벡터 (0, 1, 0, 1)에 대해 연산
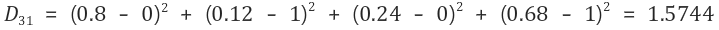

그러므로 경쟁층의 두 번째 노드를 선택하고, 두 번째 노드에 대한 가중치를 수정한다.
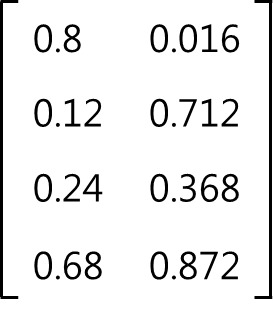
2-4) 네 번째 입력 벡터 (0, 0, 1, 0)에 대해 연산
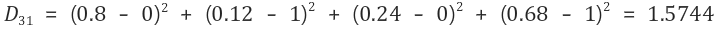
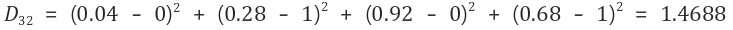
그러므로 경쟁층의 두 번째 노드를 선택하고, 두 번째 노드에 대한 가중치를 수정한다.
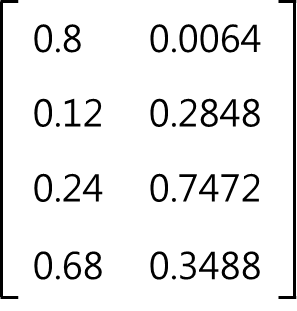
3) 최대 반복 횟수 검사
최대 반복 횟수만큼 입력 벡터에 대한 연산을 수행했으면 알고리즘을 종료하고, 그렇지 않으면 과정 4로 이동한다. 현재까지 입력 벡터에 대한 연산을 총 1회 수행했으므로, 최대 반복 횟수인 10,000번 보다 적다. 그러므로 과정 4로 이동한다.
4) 현재 입력 벡터를 첫 번째 입력 벡터로 수정
모든 입력 벡터에 대한 연산을 수행했으므로, 현재 입력 벡터는 네 번째 입력 벡터이다.최대 반복 횟수만큼 반복하지 않았으므로, 과정 5로 이동하고 학습률을 수정한 다음 과정 2로 돌아간다. 그 다음 첫 번째 입력 벡터부터 다시 입력 벡터와 경쟁층 노드의 거리를 계산하고, 각 노드의 가중치를 수정한다. 그러므로 입력 벡터에 대한 연산을 반복하기 위해 현재 입력 벡터를 첫 번째 입력 벡터로 재설정하고, 과정 5로 이동한다.
5) 학습률 수정
학습률을 아래와 같은 방법으로 수정한다.
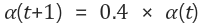
그러므로 학습률은 0.6에서 0.24로 수정된다. 그 다음 과정 2로 이동하여 입력 벡터에 대한 연산을 반복한다.
* 과정 5에서 과정 2로 이동할 때, 현재까지 계산한 가중치 행렬은 그대로 유지한다.
* 초기 학습률과 학습률의 감소 비율은 알고리즘을 설계할 때, 직관적으로 설정하는 값이다.
* 초기 학습률과 학습률의 감소 비율을 이론적으로 설정하고 싶다면, 퍼지이론(Fuzzy theory)를 참조하면 된다.
728x90'<ML>' 카테고리의 다른 글
CatboostEncoder (0) 2023.01.30