2022-06-24 반도체 박막 두께 분석.ipynb
0.33MB
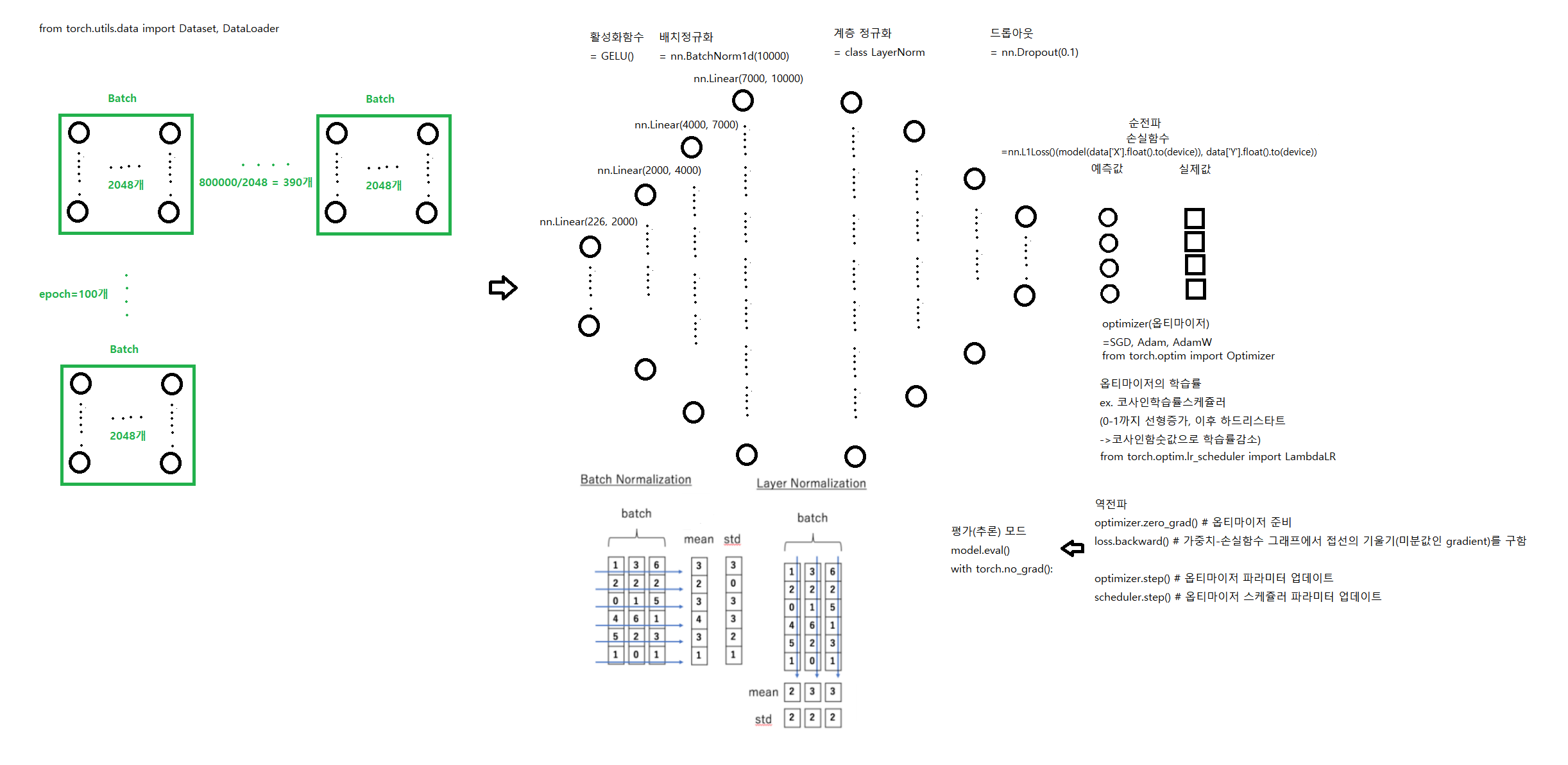
for epoch in range(epochs): # 100
total_loss = 0
total_val_loss = 0
for i, data in enumerate(tqdm(train_loader, desc='**Train mode***')): # 390
# 순전파
pred = model(data['X'].float().to(device)) # 예측값
loss = loss_fn(pred, data['Y'].float().to(device)) # 손실률
# 역전파
optimizer.zero_grad() # 옵티마이저 준비 # optimizer를 사용해 학습가능한 weight변수에 대한 모든 변화도를 0으로 만듦
loss.backward() # x축이 weight, y축이 총손실함수(평균손실률)인 가중치-손실함수 그래프에서 미분값인 gradient를 구함
optimizer.step() # 옵티마이저 파라미터 업데이트
scheduler.step() # 옵티마이저 스케쥴러 파라미터 업데이트
total_loss += loss.item() # 390개의 손실률의 합
train_loss = total_loss / len(train_loader) # 평균 손실률
print ("Epoch [{}/{}], Train Loss: {:.4f}".format(epoch+1, epochs, train_loss))
# evaluation
# validation 데이터를 부르고 epoch 마다 학습된 모델을 부르고 평가.
model.eval()
with torch.no_grad():
for i, data in enumerate(tqdm(val_loader, desc='*********Evaluation mode*******')):
pred = model(data['X'].float().to(device))
loss_val = loss_fn(pred, data['Y'].float().to(device))
total_val_loss += loss_val.item()
val_loss = total_val_loss / len(val_loader)
print ("Epoch [{}/{}], Eval Loss: {:.4f}".format(epoch+1, epochs, val_loss))